电话:020-66888888

苹果香港大学的合作团队提出了扩散语言模型的
作者:365bet登录 发布时间:2025-06-30 12:29
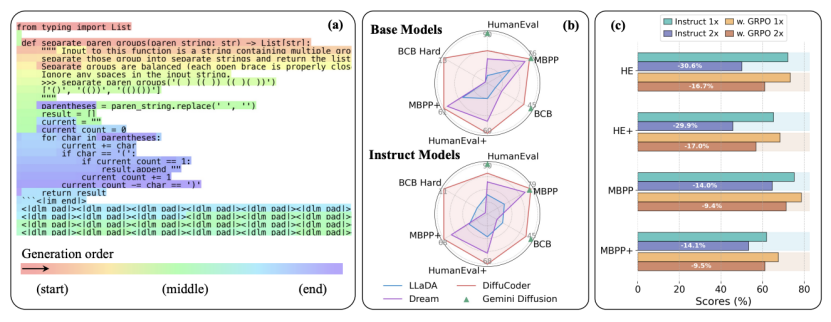 资料来源:DeepTechdiffusion语言模型(DLM,扩散语言模型)如今一直在赢得越来越多的关注。 Inception Labs推出了第一个商业级DLM水星后,Google不久前也推出了DLM Gemini扩散。由于其独特的并行生成机制,扩散模型显示了编码生成任务的巨大潜力,尤其是在提高生成速度和代码结构的优化方面。但是,对于研究人员和开发人员而言,关于语言任务(尤其是代码生成)中传播模型的内部工作机制仍然存在很多未知。他们如何计划全球?这一代过程与自我代表模型之间的本质区别是什么?如何有效优化?最近,Apple和Hong Kon Universityg的研究人员发表的一篇文章,“传播设备:理解和改进掩盖的扩散模型的编码生成”,S系统地帮助这些重要问题。在这项研究中,我们不仅启动了70亿参数的开放参数源模型模型的传播设备,还对传播模型的解码行为进行了深入的分析,并提出了有效的增强学习框架。图| (a)具有1.2采样温度的传播设备 - 扩散装置的真实解码过程的示例。 (b)编码参考结果。 (c)当解码步骤减少一半时,用组合GRPO指令训练的扩散装置与自身相比显示出性能降解(来源:ARXIV)。这种机制非常适合确保SECUECAS的一致性,但是对于固有的非线性任务(例如代码生成)存在某些局限性。编程过程通常意味着在不同的代码块之间跳跃,随后的补充结构和依赖关系的事先计划。这些是diffi邪教直接模拟自我回归模型的单向生成模式。相反,扩散模型使用了平行“消除”的迭代过程。从用掩码完全覆盖的序列开始,在多个迭代中同时评估所有位置,并逐渐用真实的单词元素代替掩码。从理论上讲,这种全局和并行生成的方法足以处理具有复杂结构单元的代码等任务。我正在这样做。为了量化扩散模型的真实产生行为,研究人员引入了一种称为“ requisitionAutomatic”(AR-NENS)的度量标准。该指标是根据两个方面进行分析的:“局部连续性”(模型的模型模式倾向于生成相邻单词的元素)和“全球顺序”(从左到右的填充趋势)。分析的结果表明,传播模型还没有完成快速单词右侧的位置,研究人员Call这种现象“熵Sumidero”。采样URA对扩散模型具有双重影响。在自我抑制模型中,高温主要用于增加单词选择的多样性。但是,在扩散模型中,温度的变化也对“将要发生的地方”的决策产生了重大影响。采样温度的升高使模型的生成顺序更加灵活和多样,并且从左到右限制较少。行为多样性的这种增加指向了随后的增强学习优化的方向。图1。通过强化学习优化代码生成的几种抽样温度(来源:ARXIV)的影响是当前方法,奖励信号通常来自单位代码测试的批准率。但是,应用算法的扩散模型应用程序标准导致较高的培训差异和不稳定性,主要是因为高计算CO需要STS准确估计生成序列的概率。为了解决这个问题,研究小组提出了一种称为“耦合组”的强化学习算法。该算法的核是引入一对互补对的抽样方案。在培训的每个步骤中,该算法为同一代码样本创建了互补的面膜对。例如,蒙版是序列中的一个奇怪程度,希望覆盖该位置,另一个掩码甚至可以准确覆盖位置。使用此设计,可以通过两个传播模型向前评估序列中的每个单词。图|扩散训练阶段的过程和耦合的示意图 - GRPO算法(来源:ARXIV)这种“耦合采样”的机制具有多个优点。首先,我们保证对所有词汇元素进行完整评估。其次,每个单词元素将在部分上下文中评估。这大大降低了概率的差异Y估计是因为它比用孤立的(完整面具)评估的更接近实际解码情况。该方法基于反假变量的统计原理,理论上保证了差异的降低,并使过程学习过程更加稳定。研究人员已经在多个代码生成参考点上验证了配电设备的性能。结果表明,与QWEN2.5编码器,OpenCoder等相比,先前经过1300亿个词的基本差异编码器模型的性能。开源回归代码模型是可比的。此外,与指令调整版本相比,联合的GPO培训模型可通过EvalPlus提高4.4%的性能(此改进仅使用21,000个培训样本)。图|参考测试的结果(来源:ARXIV)此外,分析表明,优化的模型降低了“自我分离”,并且适应于平行解码。如果将解码步骤的数量减少一半(也就是说,它将很快产生两倍),则将进一步降低优化模型的性能。这表明对模型的确切生成顺序的依赖性减少了,并且可以更好地完成扩散模型的平行生成的可能性。参考材料:1。https://arxiv.org/pdf/2506.20639 Tappting:Liu Yakun
资料来源:DeepTechdiffusion语言模型(DLM,扩散语言模型)如今一直在赢得越来越多的关注。 Inception Labs推出了第一个商业级DLM水星后,Google不久前也推出了DLM Gemini扩散。由于其独特的并行生成机制,扩散模型显示了编码生成任务的巨大潜力,尤其是在提高生成速度和代码结构的优化方面。但是,对于研究人员和开发人员而言,关于语言任务(尤其是代码生成)中传播模型的内部工作机制仍然存在很多未知。他们如何计划全球?这一代过程与自我代表模型之间的本质区别是什么?如何有效优化?最近,Apple和Hong Kon Universityg的研究人员发表的一篇文章,“传播设备:理解和改进掩盖的扩散模型的编码生成”,S系统地帮助这些重要问题。在这项研究中,我们不仅启动了70亿参数的开放参数源模型模型的传播设备,还对传播模型的解码行为进行了深入的分析,并提出了有效的增强学习框架。图| (a)具有1.2采样温度的传播设备 - 扩散装置的真实解码过程的示例。 (b)编码参考结果。 (c)当解码步骤减少一半时,用组合GRPO指令训练的扩散装置与自身相比显示出性能降解(来源:ARXIV)。这种机制非常适合确保SECUECAS的一致性,但是对于固有的非线性任务(例如代码生成)存在某些局限性。编程过程通常意味着在不同的代码块之间跳跃,随后的补充结构和依赖关系的事先计划。这些是diffi邪教直接模拟自我回归模型的单向生成模式。相反,扩散模型使用了平行“消除”的迭代过程。从用掩码完全覆盖的序列开始,在多个迭代中同时评估所有位置,并逐渐用真实的单词元素代替掩码。从理论上讲,这种全局和并行生成的方法足以处理具有复杂结构单元的代码等任务。我正在这样做。为了量化扩散模型的真实产生行为,研究人员引入了一种称为“ requisitionAutomatic”(AR-NENS)的度量标准。该指标是根据两个方面进行分析的:“局部连续性”(模型的模型模式倾向于生成相邻单词的元素)和“全球顺序”(从左到右的填充趋势)。分析的结果表明,传播模型还没有完成快速单词右侧的位置,研究人员Call这种现象“熵Sumidero”。采样URA对扩散模型具有双重影响。在自我抑制模型中,高温主要用于增加单词选择的多样性。但是,在扩散模型中,温度的变化也对“将要发生的地方”的决策产生了重大影响。采样温度的升高使模型的生成顺序更加灵活和多样,并且从左到右限制较少。行为多样性的这种增加指向了随后的增强学习优化的方向。图1。通过强化学习优化代码生成的几种抽样温度(来源:ARXIV)的影响是当前方法,奖励信号通常来自单位代码测试的批准率。但是,应用算法的扩散模型应用程序标准导致较高的培训差异和不稳定性,主要是因为高计算CO需要STS准确估计生成序列的概率。为了解决这个问题,研究小组提出了一种称为“耦合组”的强化学习算法。该算法的核是引入一对互补对的抽样方案。在培训的每个步骤中,该算法为同一代码样本创建了互补的面膜对。例如,蒙版是序列中的一个奇怪程度,希望覆盖该位置,另一个掩码甚至可以准确覆盖位置。使用此设计,可以通过两个传播模型向前评估序列中的每个单词。图|扩散训练阶段的过程和耦合的示意图 - GRPO算法(来源:ARXIV)这种“耦合采样”的机制具有多个优点。首先,我们保证对所有词汇元素进行完整评估。其次,每个单词元素将在部分上下文中评估。这大大降低了概率的差异Y估计是因为它比用孤立的(完整面具)评估的更接近实际解码情况。该方法基于反假变量的统计原理,理论上保证了差异的降低,并使过程学习过程更加稳定。研究人员已经在多个代码生成参考点上验证了配电设备的性能。结果表明,与QWEN2.5编码器,OpenCoder等相比,先前经过1300亿个词的基本差异编码器模型的性能。开源回归代码模型是可比的。此外,与指令调整版本相比,联合的GPO培训模型可通过EvalPlus提高4.4%的性能(此改进仅使用21,000个培训样本)。图|参考测试的结果(来源:ARXIV)此外,分析表明,优化的模型降低了“自我分离”,并且适应于平行解码。如果将解码步骤的数量减少一半(也就是说,它将很快产生两倍),则将进一步降低优化模型的性能。这表明对模型的确切生成顺序的依赖性减少了,并且可以更好地完成扩散模型的平行生成的可能性。参考材料:1。https://arxiv.org/pdf/2506.20639 Tappting:Liu Yakun 下一篇:没有了